|
|
||||||
|
||||||
Glyphs’ recognitionby Andrew KirillovThe article describes glyphs’ recognition algorithm and its application in 2D augmented reality. |
Posted: November 5, 2010 Programming languages: C# AForge.NET framework: 2.1.4 |

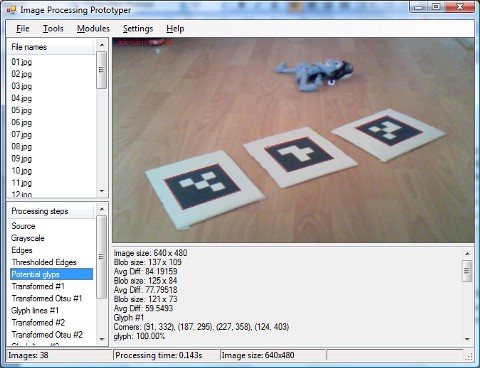
IntroductionRecognition of glyphs (or optical glyphs as they are called most frequently) is quite an intersection topic, which has applications in a range of different areas. The most popular application of optical glyphs is augmented reality, where computer vision algorithm finds them in a video stream and substitutes with artificially generated objects creating a view which is half real and half virtual – virtual objects in a real world. Another area of optical glyphs’ application is robotics, where glyphs can be used to give commands to a robot or help robot to navigate within some environment, where glyphs can be used to give robot directions. The technology behind optical glyph recognition, used in augmented reality, can revolutionize the casino gaming experience. By integrating this tech, online 바카라 사이트 can offer a more immersive, interactive gaming environment, where virtual elements blend seamlessly with real-world aspects, elevating the engagement and enjoyment for players in this digital era. Here is one of the nice demos of optical glyphs’ application: In this article we are going to discuss an algorithm for optical glyph recognition, which is the first step towards all the applications based on optical glyphs. For some applications it may be the first and the only step, since recognition is the only thing which may be required. But for others, like 3D augmented reality, it will be just a beginning. For algorithm prototyping and testing I’ve used an IPPrototyper application, which is part of the AForge.NET framework. As usually it really simplified testing of the algorithm on many images and allowed to concentrate on the idea itself, but not on some other unwanted coding.
Below is a sample of some glyphs which we are aiming to recognize. All glyphs are represented with a square grid divided equally to the same number of rows and columns. Each cell of the grid is filled with either black or white color. The first and the last row/column of each glyph contains only black cells, which creates a black border around each glyph. Also we do an assumption that every row and column has at least one white cell, so there are no completely black rows and columns (except the first and the last). All such glyphs are printed on white paper in such a way, that there is white area around black borders of a glyph (the above picture of IPPrototypes shows how they look like when printed).
Finding potential glyphsBefore going into glyph recognition, there is another task which needs to be solved first – find potential glyphs in an image to recognize. The aim of the task is to find all quadrilateral areas which may look like a glyph – an area which is promising enough for further analysis and recognition. In other words, we need to find 4 corners of each glyph in the source image. It so happened that this task is the hardest one from the entire glyph searching-recognition project. The first step is trivial – we’ll do grayscaling of the original image, since it will reduce amount of data to process, plus we don’t need color information for this task anyway. What is next? As we can see all glyphs are quite contrast objects – a black bordered glyph on white paper. So most probably a good direction is to search for black quadrilaterals surrounded by white areas and do their analysis. However, how to find them? One of the ideas is to try doing thresholding and then blob analysis for finding black quadrilaterals. Of course we are not going to use regular thresholding with predefined threshold since it will give us nothing – we simply can not set one threshold value for all possible light and environment conditions. Trying Otsu thresholding may produce some good results:
As we can see on the pictures above, the Otsu thresholding did its work quite well – we got black quadrilaterals surrounded by white areas. Using blob counter it is possible to find all the black objects on the above binary images, perform some checks to make sure these objects are quadrilaterals, etc. etc. It is really possible to get everything working starting from this point, however it may have some issues. The problem is that Otsu thresholding worked for the above images and it actually works for many other images. But not for all of them. Here is one of the images, where it does not work as supposed and all the idea fails.
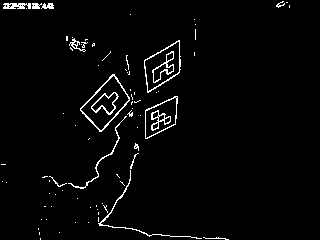
The above picture shows that global thresholding does not work very well for certain illumination/environment conditions. So we may need to find another idea. As it was already mentioned, optical glyphs are quite contrast objects – black glyph surrounded by white area. Of course the contrast may change depending on light conditions and black areas may get lighter, but white areas may get darker. But still the difference should be considerable enough unless we have absolutely bad illumination. So instead of trying to find black or white quadrilaterals, we may try to find regions where image brightness changes sharply. This is the work for edge detector, for example Difference Edge Detector:
To get rid of the areas where image brightness changes insignificantly we will do thresholding. Here is how it looks like with the 3 samples we’ve started from:
As we can see on the pictures above, all the detected glyphs are represented by a stand alone blob forming quadrilateral. In the case if illumination condition is not completely bad, all these glyphs’ quadrilaterals have a well connected edge, so they are really represented with a single blob, which will be easy to extract with a blob counting algorithms. Below is an example of bad illumination conditions, where both Otsu thresholding and thresholded edge detection fail to produce any good result which could be used for further glyph location and recognition.
So we decide to go with edge detection and hence here is the beginning of our code (we will use UnmanagedImage to avoid extra locks/unlocks of .NET’s managed image): // 1 - grayscaling
UnmanagedImage grayImage = null;
if ( image.PixelFormat == PixelFormat.Format8bppIndexed )
{
grayImage = image;
}
else
{
grayImage = UnmanagedImage.Create( image.Width, image.Height,
PixelFormat.Format8bppIndexed );
Grayscale.CommonAlgorithms.BT709.Apply( image, grayImage );
}
// 2 - Edge detection
DifferenceEdgeDetector edgeDetector = new DifferenceEdgeDetector( );
UnmanagedImage edgesImage = edgeDetector.Apply( grayImage );
// 3 - Threshold edges
Threshold thresholdFilter = new Threshold( 40 );
thresholdFilter.ApplyInPlace( edgesImage );
Now, when we have a binary image containing significant edges of all objects, we need to process all the blobs formed by these edges and check if any of the blobs may represent an edge of a glyph. To go through all separate blobs we can use BlobCounter: // create and configure blob counter
BlobCounter blobCounter = new BlobCounter( );
blobCounter.MinHeight = 32;
blobCounter.MinWidth = 32;
blobCounter.FilterBlobs = true;
blobCounter.ObjectsOrder = ObjectsOrder.Size;
// 4 - find all stand alone blobs
blobCounter.ProcessImage( edgesImage );
Blob[] blobs = blobCounter.GetObjectsInformation( );
// 5 - check each blob
for ( int i = 0, n = blobs.Length; i < n; i++ )
{
// ...
}
As we can see from the binary edge images we got, we have lots of edges. But not all of them form a quadrilateral looking object. We are interested only in quadrilateral looking blobs, because a glyph will be always represented by a quadrilateral regardless of how it is rotated. To make a check for quadrilateral, we can collect blob’s edge points using GetBlobsEdgePoints() and then use IsQuadrilateral() method for checking if these points may form a quadrilateral. If not, then we skip the blob and go to then next one. List<IntPoint> edgePoints = blobCounter.GetBlobsEdgePoints( blobs[i] );
List<IntPoint> corners = null;
// does it look like a quadrilateral ?
if ( shapeChecker.IsQuadrilateral( edgePoints, out corners ) )
{
// ...
}
OK, now we have all blobs which look like quadrilaterals. However not every quadrilateral is a glyph. As we already mentioned, a glyph has a black border and it is printed on white paper. So we need to make a check that a blob we have is black inside, but white outside. Or, to be more correct, it should be much darker inside than outside (since illumination may vary and checking for perfect white/black will not work). To perform a check if blob is darker inside than outside, we may get left and right edge points of the blob using GetBlobsLeftAndRightEdges() method and then calculate average difference of brightness between pixels just outside of the blob and inside. If the average difference is significant enough, then most likely we have a dark object surrounded by lighter area. // get edge points on the left and on the right side
List<IntPoint> leftEdgePoints, rightEdgePoints;
blobCounter.GetBlobsLeftAndRightEdges( blobs[i],
out leftEdgePoints, out rightEdgePoints );
// calculate average difference between pixel values from outside of the
// shape and from inside
float diff = CalculateAverageEdgesBrightnessDifference(
leftEdgePoints, rightEdgePoints, grayImage );
// check average difference, which tells how much outside is lighter than
// inside on the average
if ( diff > 20 )
{
// ...
}
To clarify the idea of calculating average difference between pixels outside and inside of a blob, lets take a closer look at the CalculateAverageEdgesBrightnessDifference() method. For both left and right edges of a blob, the method builds two lists of points – list of points which are a bit on the left from the edge and list of points which are a bit on the right from the edge (lets say 3 pixel away from the edge). For each of the lists of points it collects pixel values corresponding to these points using Collect8bppPixelValues() method. And then it calculates average difference – for left blob’s edge it subtracts value of the pixel on the right side of the edge (inside of the blob) from value of the pixel on the left side of the edge (outside of the blob); for right blob’s edge it does opposite difference. When calculation is done the method produces a value, which is an average difference between pixels outside and inside of a blob. const int stepSize = 3;
// Calculate average brightness difference between pixels outside and
// inside of the object bounded by specified left and right edge
private float CalculateAverageEdgesBrightnessDifference(
List<IntPoint> leftEdgePoints,
List<IntPoint> rightEdgePoints,
UnmanagedImage image )
{
// create list of points, which are a bit on the left/right from edges
List<IntPoint> leftEdgePoints1 = new List<IntPoint>( );
List<IntPoint> leftEdgePoints2 = new List<IntPoint>( );
List<IntPoint> rightEdgePoints1 = new List<IntPoint>( );
List<IntPoint> rightEdgePoints2 = new List<IntPoint>( );
int tx1, tx2, ty;
int widthM1 = image.Width - 1;
for ( int k = 0; k < leftEdgePoints.Count; k++ )
{
tx1 = leftEdgePoints[k].X - stepSize;
tx2 = leftEdgePoints[k].X + stepSize;
ty = leftEdgePoints[k].Y;
leftEdgePoints1.Add( new IntPoint(
( tx1 < 0 ) ? 0 : tx1, ty ) );
leftEdgePoints2.Add( new IntPoint(
( tx2 > widthM1 ) ? widthM1 : tx2, ty ) );
tx1 = rightEdgePoints[k].X - stepSize;
tx2 = rightEdgePoints[k].X + stepSize;
ty = rightEdgePoints[k].Y;
rightEdgePoints1.Add( new IntPoint(
( tx1 < 0 ) ? 0 : tx1, ty ) );
rightEdgePoints2.Add( new IntPoint(
( tx2 > widthM1 ) ? widthM1 : tx2, ty ) );
}
// collect pixel values from specified points
byte[] leftValues1 = image.Collect8bppPixelValues( leftEdgePoints1 );
byte[] leftValues2 = image.Collect8bppPixelValues( leftEdgePoints2 );
byte[] rightValues1 = image.Collect8bppPixelValues( rightEdgePoints1 );
byte[] rightValues2 = image.Collect8bppPixelValues( rightEdgePoints2 );
// calculate average difference between pixel values from outside of
// the shape and from inside
float diff = 0;
int pixelCount = 0;
for ( int k = 0; k <leftEdgePoints.Count; k++ )
{
if ( rightEdgePoints[k].X - leftEdgePoints[k].X > stepSize * 2 )
{
diff += ( leftValues1[k] - leftValues2[k] );
diff += ( rightValues2[k] - rightValues1[k] );
pixelCount += 2;
}
}
return diff / pixelCount;
}
Now it is time to take a look at the result of the two checks we made – for quadrilateral and for average difference between pixels inside and outside of a blob. Let’s highlight edges of all the blobs which pass these checks and see if we get any closer to detection of glyphs’ location.
Taking a look at the above pictures we can see that result of the two checks we made is really acceptable – only blobs containing optical glyphs were highlighted and nothing else. Potentially it may happen that some other objects may satisfy those checks and the algorithm may find some other dark quadrilaterals surrounded by white areas. However experiments show it does not happen so often. Even if happens sometimes, there is still further glyph recognition step involved, which may filter “false” glyphs. So, we decide that we have quite good glyph (or better say potential glyph) localization algorithm and can move further into recognition. Glyph recognitionNow, when we have coordinates of potential glyphs (its quadrilaterals), we can do their actual recognition. It is possible to develop an algorithm, which does glyph recognition directly in the source image. However, let’s simplify things a bit and extract glyphs from the source image, so we have a separate square image for each potential glyph, containing only glyph data. This can be done using QuadrilateralTransformation. Below are the few glyphs extracted from some of the previously processed images: // 6 - do quadrilateral transformation
QuadrilateralTransformation quadrilateralTransformation =
new QuadrilateralTransformation( quadrilateral, 100, 100 );
UnmanagedImage glyphImage = quadrilateralTransformation.Apply( image );
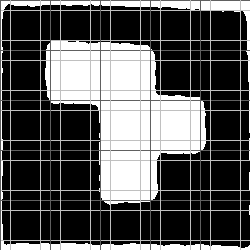
As we can see from the pictures above, illumination conditions may vary quite a lot and some glyphs may not be so contrast as others. So we may use Otsu thresholing on this stage to binarize glyphs. // otsu thresholding OtsuThreshold otsuThresholdFilter = new OtsuThreshold( ); otsuThresholdFilter.ApplyInPlace( glyphImage ); At this stage we are ready to go into final glyph recognition. There are different possible ways exist to do this, like shape recognition, template matching, etc. Although there may be benefits of using things like shape recognition, I found them a bit too complex for such a simple task of recognizing a glyph satisfying constraints we made from there very beginning. As it was mentioned before, all our glyphs are represented by a square grid, where each cell is filled with black or white color. So a recognition algorithm can be made quite simple with this assumption – just divide glyph image into cells and check what is the average (most common) color of the cell. Before we go into glyph recognition code, let’s do some clarification to the way we divide glyph into cells. For example, let’s take a look at the image below. Here we can see how glyph is divided by dark gray lines into 5×5 grid of cells having same width and height. So what we could do is just to count number of white pixels in each such cell and check if the number is greater than half of the cell’s area. If it is greater, then we assume that the cell is filled by white color, which corresponds to “1” lets say. And if the number is less than half of the cell’s area, then we have a black filled cell, which corresponds to “0”. Also we may introduce confidence level for each cell – if the entire cell is filled with white or black pixels, then we are 100% confident about cell’s color/type. However, if a cell has 60% of white pixels and 40% of black pixels, then recognition confidence drops to 60%. When a cell is half filled with white and half filled with black color, then confidence equals to 50%, which means we are not sure at all about cell color/type.
However, with the above described approach it will be hardly possible to find a cell, which may give 100% confidence level. As we can see from the picture above, all the process of glyph localization, extraction, thresholding, etc. may cause some imperfections – some edge cells may contain also parts of white areas surrounding a glyph, but some inner cells which are supposed to be black may contain white pixels caused by neighboring white cells, etc. So instead of calculating number of white pixels over entire cell’s area, we may introduce small gap around cell’s borders and exclude it from processing. The above picture demonstrates the idea with gaps – instead of scanning entire cell which is highlighted by dark gray lines, we scan smaller inner area which is highlighted with light gray lines. Now, when the recognition idea seems to be clear, we can get to its implementation. First of all the code goes throw the provided image and calculates sum of pixels’ values for each cell. Then these sums are used to calculate fullness of each cell – how full is a cell filled with white pixels. Finally cell’s fullness is used to determine its type (“1” – white filled or “0” – black filled) and confidence level. Note: before using this function (method), user must set glyph size to recognize. public byte[,] Recognize( UnmanagedImage image, Rectangle rect,
out float confidence )
{
int glyphStartX = rect.Left;
int glyphStartY = rect.Top;
int glyphWidth = rect.Width;
int glyphHeight = rect.Height;
// glyph's cell size
int cellWidth = glyphWidth / glyphSize;
int cellHeight = glyphHeight / glyphSize;
// allow some gap for each cell, which is not scanned
int cellOffsetX = (int) ( cellWidth * 0.2 );
int cellOffsetY = (int) ( cellHeight * 0.2 );
// cell's scan size
int cellScanX = (int) ( cellWidth * 0.6 );
int cellScanY = (int) ( cellHeight * 0.6 );
int cellScanArea = cellScanX * cellScanY;
// summary intensity for each glyph's cell
int[,] cellIntensity = new int[glyphSize, glyphSize];
unsafe
{
int stride = image.Stride;
byte* srcBase = (byte*) image.ImageData.ToPointer( ) +
( glyphStartY + cellOffsetY ) * stride +
glyphStartX + cellOffsetX;
byte* srcLine;
byte* src;
// for all glyph's rows
for ( int gi = 0; gi < glyphSize; gi++ )
{
srcLine = srcBase + cellHeight * gi * stride;
// for all lines in the row
for ( int y = 0; y < cellScanY; y++ )
{
// for all glyph columns
for ( int gj = 0; gj < glyphSize; gj++ )
{
src = srcLine + cellWidth * gj;
// for all pixels in the column
for ( int x = 0; x < cellScanX; x++, src++ )
{
cellIntensity[gi, gj] += *src;
}
}
srcLine += stride;
}
}
}
// calculate value of each glyph's cell and set
// glyphs' confidence to minim value of cell's confidence
byte[,] glyphValues = new byte[glyphSize, glyphSize];
confidence = 1f;
for ( int gi = 0; gi < glyphSize; gi++ )
{
for ( int gj = 0; gj < glyphSize; gj++ )
{
float fullness = (float)
( cellIntensity[gi, gj] / 255 ) / cellScanArea;
float conf = (float) System.Math.Abs( fullness - 0.5 ) + 0.5f;
glyphValues[gi, gj] = (byte) ( ( fullness > 0.5f ) ? 1 : 0 );
if ( conf < confidence )
confidence = conf;
}
}
return glyphValues;
}
With the function provided above, the next step after glyph’s binarization looks quite simple: // recognize raw glyph
float confidence;
byte[,] glyphValues = binaryGlyphRecognizer.Recognize( glyphImage,
new Rectangle( 0, 0, glyphImage.Width, glyphImage.Height ), out confidence );
At this stage we have a 2D byte array containing “0” and “1” elements corresponding to black and white cells of a glyph’s image. For example, the function should provide result shown below for the above shown glyph image: 0 0 0 0 0 0 1 1 0 0 0 0 1 1 0 0 0 1 0 0 0 0 0 0 0 Now, let’s do some checks to make sure we processed a glyph image satisfying constraints we set in the beginning. First, let’s check confidence level – if it is lower than certain limit (for example 0.6, which corresponds to 60%), then we skip the processed object. Also we skip it in the case if the glyph does not have a border made of black cells (if glyph data contains at least single “1” value in the first/last row or column) or if it does not have at least one white cell in any inner row or column. if ( confidence >= minConfidenceLevel )
{
if ( ( CheckIfGlyphHasBorder( glyphValues ) ) &&
( CheckIfEveryRowColumnHasValue( glyphValues ) ) )
{
// ...
// further processing
}
}
That is it about glyph data extraction/recognition. If a candidate image containing potential glyph has passed all the steps and checks, then it seems we really got a glyph. Matching found glyph with database of glyphsAlthough we did extraction of glyph data from an image, this is not the last step in glyph recognition task. Applications dealing with augmented reality or robotics usually have a database of glyphs, where each glyph may have its own meaning. For example, in augmented reality each glyph is associated with a virtual object to be shown instead of a glyph, but in robotics applications each glyph may represent a command or direction for a robot. So the last step is to match the extracted glyph data with a database of glyphs and retrieve information related with the glyph – it’s ID, name, whatever else. To complete glyph matching step successfully, we need to keep in mind that glyphs can be rotated, so comparing extracted glyph data one to one with glyphs stored in database will not work. Finding a matching glyph in glyphs’ database we need to do 4 compares of extracted glyph data with every glyph in the database – compare 4 possible rotations of extracted glyph data with the database. Another important thing to mention is that all glyphs in database should be rotation variant in order to be unique regardless of rotation. If a glyph may look the same after rotation then it is a rotation invariant glyph. For rotation invariant glyphs we cannot determine their rotation angle, which is very important for applications like augmented reality. Also it may not be possible to find correct matching glyph in a database, if it contains few rotation invariant glyphs, which may look the same if one of them is rotated. Below picture demonstrates some rotation variant and invariant glyphs. Glyphs (1) and (2) are rotation variant – if they are rotated they will look different always. Glyphs (3), (4) and (5) are rotation invariant – if rotated they will look the same, so it is not possible to detect their rotation angle. Also we may see that glyph (4) is actually same as glyph (5), but just rotated, so glyph database should not contain them both (even if it would be rotation variant glyph).
Now, when it is clear that all glyphs must be rotation variant and that we need to perform 4 compares per glyph in a database in order to find a match, we can go to implementation of matching routine. public int CheckForMatching( byte[,] rawGlyphData )
{
int size = rawGlyphData.GetLength( 0 );
int sizeM1 = size - 1;
bool match1 = true;
bool match2 = true;
bool match3 = true;
bool match4 = true;
for ( int i = 0; i < size; i++ )
{
for ( int j = 0; j < size; j++ )
{
byte value = rawGlyphData[i, j];
// no rotation
match1 &= ( value == data[i, j] );
// 180 deg
match2 &= ( value == data[sizeM1 - i, sizeM1 - j] );
// 90 deg
match3 &= ( value == data[sizeM1 - j, i] );
// 270 deg
match4 &= ( value == data[j, sizeM1 - i] );
}
}
if ( match1 )
return 0;
else if ( match2 )
return 180;
else if ( match3 )
return 90;
else if ( match4 )
return 270;
return -1;
}
As we can see from the code above, the method returns -1 if provided glyph data don’t match to the data kept in data variable (member of a glyph class). However, if the matching is found than it returns rotation angle (0, 90, 180 or 270 degrees in counter clockwise direction) which is used to get the specified glyph data from the original glyph we match to. Now, all we need to do is to go through all glyphs in a database and check if the glyph data we extracted from image matches to any of the glyphs from the database. If matching is found, then we can get all the data associated with the matched glyph and use it for visualization, giving command to robot, etc. That is all about glyph recognition. Now it is time for a small demo, which demonstrates all the above code applied to a video feed (the code highlights recognized glyphs with a border and displays their names). 2D Augmented RealityNow, when we have glyph recognition working, we may try doing some fun. We will not do 3D augmented reality this time, but start with 2D augmented reality. It will not be hard to do it since we have all the things we need for this. The first thing we need to do is to correct glyph’s quadrilateral (the one we got from IsQuadrilateral() call on the glyph localization phase). As it was already mentioned the glyph we extract from the found quadrilateral may not look exactly the same as in glyphs’ database, but may be rotated. So we need to rotate quadrilateral in such a way, that a glyph extracted from it would look exactly as in database. For this purpose we need to use rotation angle provided by CheckForMatching() call we did on glyph matching phase: if ( rotation != -1 )
{
foundGlyph.RecognizedQuadrilateral = foundGlyph.Quadrilateral;
// rotate quadrilateral's corners
while ( rotation > 0 )
{
foundGlyph.RecognizedQuadrilateral.Add( foundGlyph.RecognizedQuadrilateral[0] );
foundGlyph.RecognizedQuadrilateral.RemoveAt( 0 );
rotation -= 90;
}
}
All we need to do now to complete 2D augmented reality is to put an image we want into the corrected quadrilateral. For this purpose we use BackwardQuadrilateralTransformation – same as QuadrilateralTransformation, but instead of extracting image from the specified quadrilateral it puts another image into it. // put glyph's image onto the glyph using quadrilateral transformation
BackwardQuadrilateralTransformation quadrilateralTransformation =
new BackwardQuadrilateralTransformation( );
quadrilateralTransformation.SourceImage = glyphImage;
quadrilateralTransformation.DestinationQuadrilateral = glyphData.RecognizedQuadrilateral;
quadrilateralTransformation.ApplyInPlace( sourceImage );
That was quick. Nothing else to say about 2D augmented reality after all mentioned before. So let’s see another demo … ConclusionI really hope that information in this article will be somehow useful to all those, who start projects related to glyph recognition or just learn about computer vision. Personally I learnt a lot doing the project and hope all the above written will make use not only for me. As it was already mentioned, the complexity of glyph recognition in image or video frame is not in glyph recognition itself, but in its localization. It is the hardest part to find a quadrilateral, which may contain a glyph. I tried different approaches for this and found that edge detection seems to work best of all. However, there are still cases (primarily related to bad illumination conditions), when this technique fails as well. So glyph localization still stays an actual area to revisit and improve. To get complete source code of all the algorithms and applications doing glyphs recognition, check the GRATF project, which is an open source project created as a result of all the ideas above. |
||||||||||||||||||||||||||||||